
I am a third-year PhD student (graduating in Spring'2024) between Meta AI
and
the WILLOW team at Inria Paris and École Normale
Supérieure (ENS), advised by Jean
Ponce and Yann
LeCun.
My research interests lie between theory and practice of self-supervised learning from visual inputs.
I strongly believe that vision is a core component of human intelligence and that future AI systems
will understand the world by self-learning from visual data such as images and videos.
I am currently on the job market seeking research opportunities in both academia and the industry.
If you'd like to chat, please don't hesitate to reach out to me.
I have received a MSc degree
in Mathematics, Vision and Learning, a BSc in
theoritical computer
science from ENS Paris-Saclay, and a BSc in
mathematics
and computer
science from University Paris-Est Creteil. I have interned at
Carnegie Mellon University
in the Robotics Institute working with Martiel Hebert and Yu-Xiong Wang on few-shot learning in computer vision.
Research
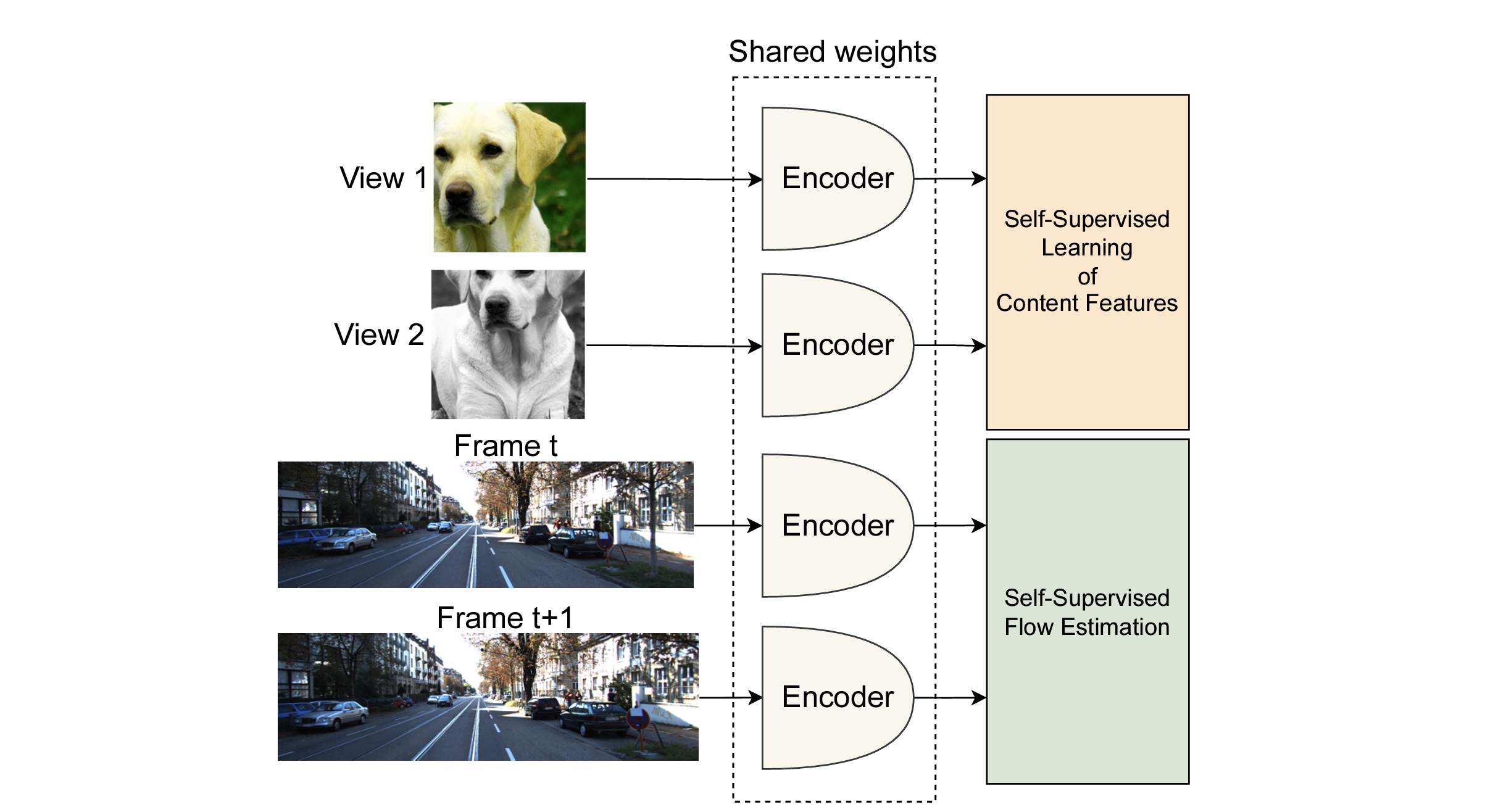
arxiv 2023
@inproceedings{bardes2023mcjepa,
title = {MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features},
author = {Adrien Bardes and Jean Ponce and Yann LeCun},
booktitle={arXiv preprint arXiv:2307.12698}
year = {2023},
}
Self-supervised learning of visual representations has been focusing on learning content features, which do not capture object motion or location, and focus on identifying and differentiating objects in images and videos. On the other hand, optical flow estimation is a task that does not involve understanding the content of the images on which it is estimated. We unify the two approaches and introduce MC-JEPA, a joint-embedding predictive architecture and self-supervised learning approach to jointly learn optical flow and content features within a shared encoder, demonstrating that the two associated objectives; the optical flow estimation objective and the self-supervised learning objective; benefit from each other and thus learn content features that incorporate motion information. The proposed approach achieves performance on-par with existing unsupervised optical flow benchmarks, as well as with common self-supervised learning approaches on downstream tasks such as semantic segmentation of images and videos.

ICML Tutorials 2023
@inproceedings{balestriero2023cokbook,
title = {A Cookbook of Self-Supervised Learning},
author = {Randall Balestriero, Mark Ibrahim, Vlad Sobal, Ari Morcos, Shashank Shekhar, Tom Goldstein, Florian Bordes,
Adrien Bardes, Gregoire Mialon, Yuandong Tian, Avi Schwarzschild, Andrew Gordon Wilson, Jonas Geiping,
Quentin Garrido, Pierre Fernandez, Amir Bar, Hamed Pirsiavash, Yann LeCun, Micah Goldblum},
booktitle={arXiv preprint arXiv:2304.12210}
year = {2023},
}
Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
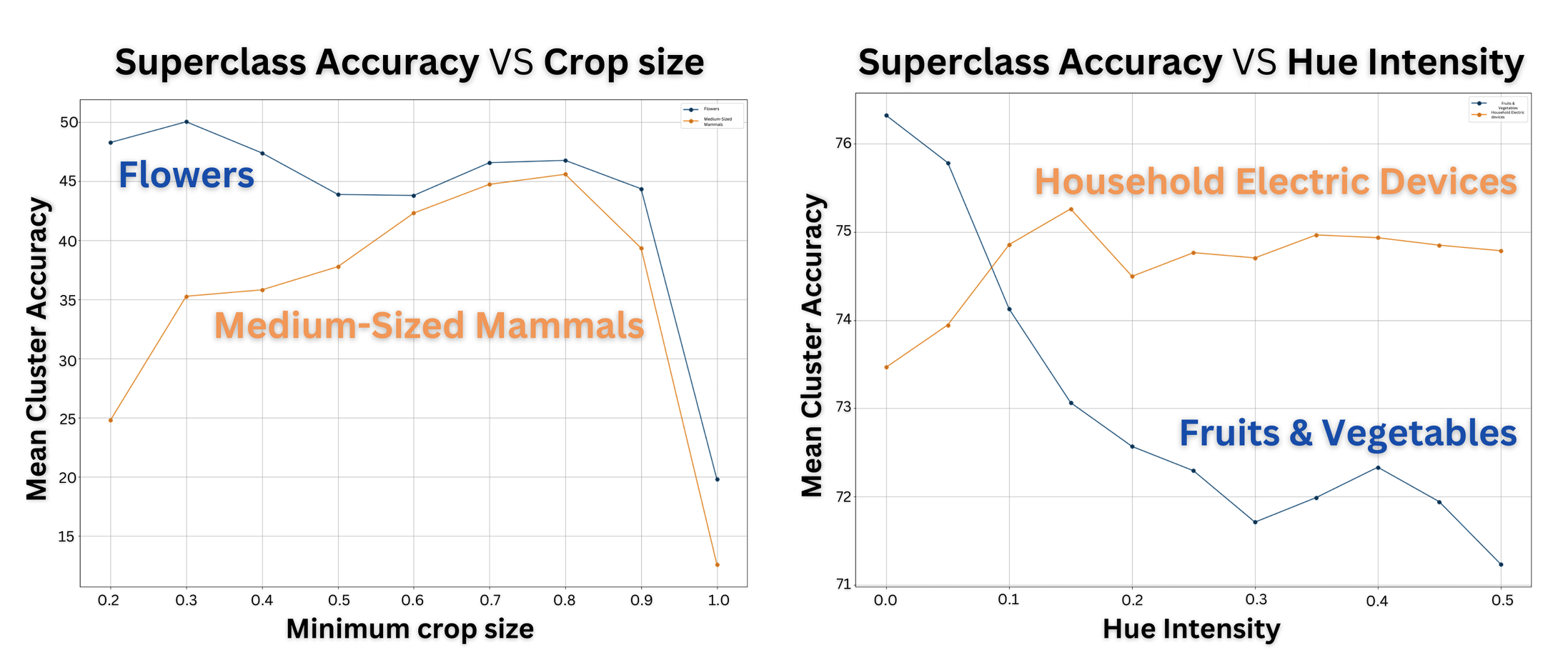
arvix 2023
@article{bendidi2023nfl,
title = {No Free Lunch in Self-Supervised Representation Learning},
author = {Ihab Bendidi and Adrien Bardes and Ethan Cohen and Alexis Lamiable and Guillaume Bollot and Auguste Genovesio},
booktitle={arXiv preprint arXiv:2304.11718}
year = {2023},
}
Self-supervised representation learning in computer vision relies heavily on hand-crafted image transformations to learn meaningful and invariant features. However few extensive explorations of the impact of transformation design have been conducted in the literature. In particular, the dependence of downstream performances to transformation design has been established, but not studied in depth. In this work, we explore this relationship, its impact on a domain other than natural images, and show that designing the transformations can be viewed as a form of supervision. First, we demonstrate that not only do transformations have an effect on downstream performance and relevance of clustering, but also that each category in a supervised dataset can be impacted in a different way. Following this, we explore the impact of transformation design on microscopy images, a domain where the difference between classes is more subtle and fuzzy than in natural images. In this case, we observe a greater impact on downstream tasks performances. Finally, we demonstrate that transformation design can be leveraged as a form of supervision, as careful selection of these by a domain expert can lead to a drastic increase in performance on a given downstream task.
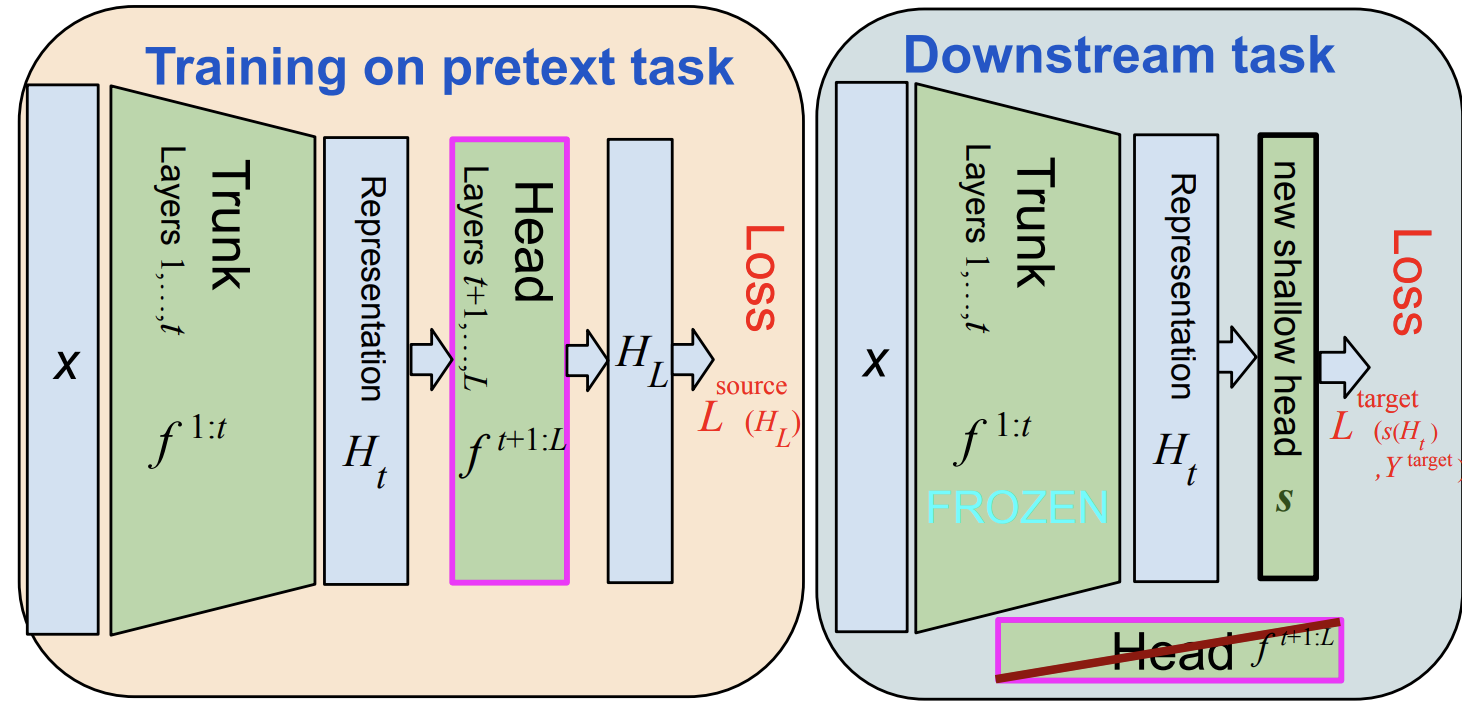
TMLR, 2023
@article{bordes2023guillotine,
title = {Guillotine Regularization: Why Removing Layers is Needed to Improve Generalization in Self-Supervised Learning},
author = {Florian Bordes and Randall Balestriero and Quentin Garrido and Adrien Bardes and Pascal Vincent},
journal={TMLR}
year = {2023},
}
One unexpected technique that emerged in recent years consists in training a Deep Network (DN) with a Self-Supervised Learning (SSL) method, and using this network on downstream tasks but with its last few layers entirely removed. This usually skimmed-over trick is actually critical for SSL methods to display competitive performances. For example, on ImageNet classification, more than 30 points of percentage can be gained that way. This is a little vexing, as one would hope that the network layer at which invariance is explicitly enforced by the SSL criterion during training (the last layer) should be the one to use for best generalization performance downstream. But it seems not to be, and this study sheds some light on why. This trick, which we name Guillotine Regularization (GR), is in fact a generically applicable form of regularization that has also been used to improve generalization performance in transfer learning scenarios. In this work, through theory and experiments, we formalize GR and identify the underlying reasons behind its success in SSL methods. Our study shows that the use of this trick is essential to SSL performance for two main reasons: (i) improper data-augmentations to define the positive pairs used during training, and/or (ii) suboptimal selection of the hyper-parameters of the SSL loss.

arvix 2022
@article{chen2022intra,
title = {Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding},
author = {Yubei Chen and Adrien Bardes and Zengyi Li and Yann LeCun},
journal={arXiv preprint arXiv:2206.08954}
year = {2022},
}
Recently, self-supervised learning (SSL) has achieved tremendous empirical advancements in learning image representation. However, our understanding and knowledge of the representation are still limited. This work shows that the success of the SOTA siamese-network-based SSL approaches is primarily based on learning a representation of image patches. Particularly, we show that when we learn a representation only for fixed-scale image patches and aggregate different patch representations linearly for an image (instance), it can achieve on par or even better results than the baseline methods on several benchmarks. Further, we show that the patch representation aggregation can also improve various SOTA baseline methods by a large margin. We also establish a formal connection between the SSL objective and the image patches co-occurrence statistics modeling, which supplements the prevailing invariance perspective. By visualizing the nearest neighbors of different image patches in the embedding space and projection space, we show that while the projection has more invariance, the embedding space tends to preserve more equivariance and locality. Finally, we propose a hypothesis for the future direction based on the discovery of this work.
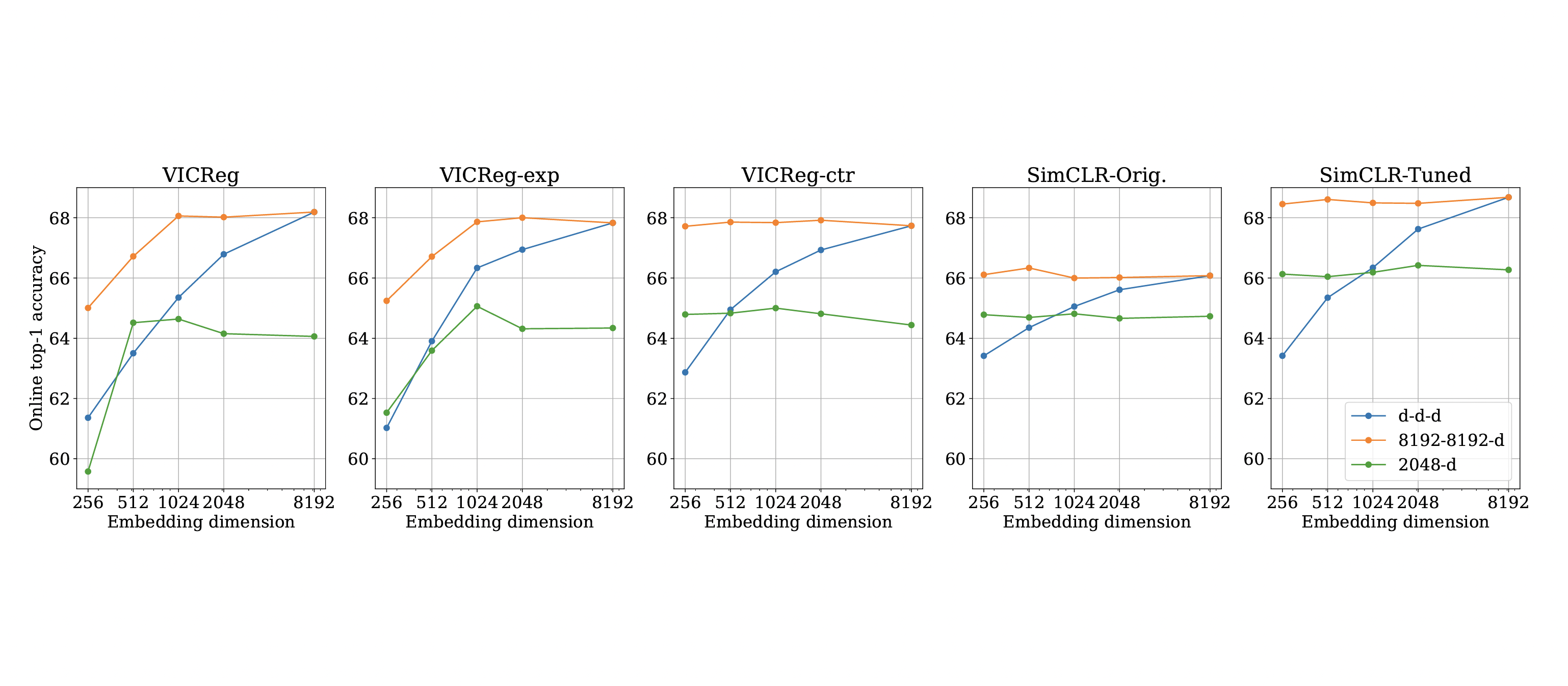
ICLR 2023 (Best paper award honorable mention)
@inproceedings{garrido2023duality,
title = {On the duality between contrastive and non-contrastive self-supervised learning},
author = {Quentin Garrido and Yubei Chen and Adrien Bardes and Laurent Najman and Yann Lecun},
article={ICLR}
year = {2023},
}
Recent approaches in self-supervised learning of image representations can be categorized into different families of methods and, in particular, can be divided into contrastive and non-contrastive approaches. While differences between the two families have been thoroughly discussed to motivate new approaches, we focus more on the theoretical similarities between them. By designing contrastive and covariance based non-contrastive criteria that can be related algebraically and shown to be equivalent under limited assumptions, we show how close those families can be. We further study popular methods and introduce variations of them, allowing us to relate this theoretical result to current practices and show the influence (or lack thereof) of design choices on downstream performance. Motivated by our equivalence result, we investigate the low performance of SimCLR and show how it can match VICReg's with careful hyperparameter tuning, improving significantly over known baselines. We also challenge the popular assumptions that contrastive and non-contrastive methods, respectively, need large batch sizes and output dimensions. Our theoretical and quantitative results suggest that the numerical gaps between contrastive and non-contrastive methods in certain regimes can be closed given better network design choices and hyperparameter tuning. The evidence shows that unifying different SOTA methods is an important direction to build a better understanding of self-supervised learning.
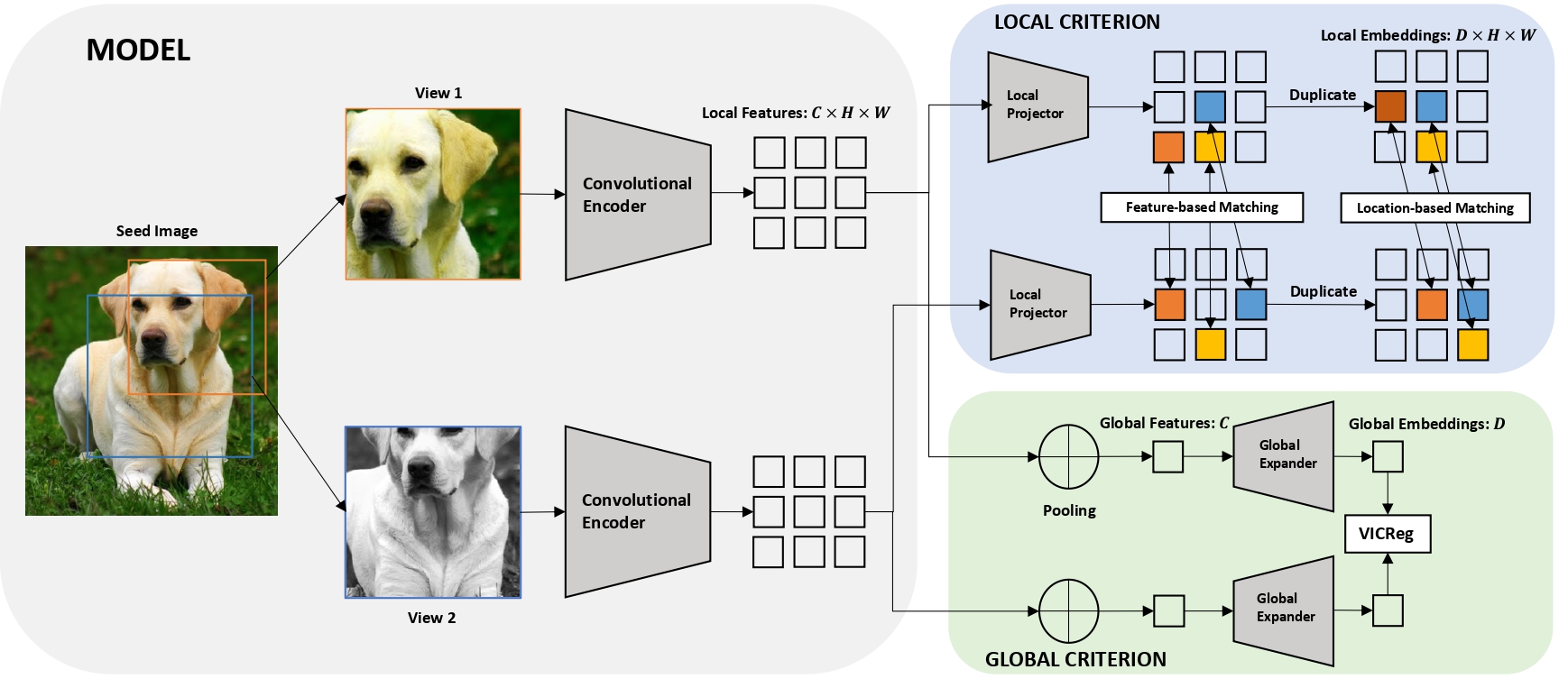
NeurIPS 2022
@inproceedings{bardes2022vicregl,
title = {VICRegL: Self-Supervised Learning of Local Visual Features},
author = {Adrien Bardes and Jean Ponce and Yann LeCun},
booktitle={arXiv preprint arXiv:2206.08155}
year = {2022},
}
Most recent self-supervised methods for learning image representations focus on either producing a global feature with invariance properties, or producing a set of local features. The former works best for classification tasks while the latter is best for detection and segmentation tasks. This paper explores the fundamental trade- off between learning local and global features. A new method called VICRegL is proposed that learns good global and local features simultaneously, yielding excellent performance on detection and segmentation tasks while maintaining good performance on classification tasks. Concretely, two identical branches of a standard convolutional net architecture are fed two differently distorted versions of the same image. The VICReg criterion is applied to pairs of global feature vectors. Simultaneously, the VICReg criterion is applied to pairs of local feature vectors occurring before the last pooling layer. Two local feature vectors are attracted to each other if their l2-distance is below a threshold or if their relative locations are consistent with a known geometric transformation between the two input images. We demonstrate strong performance on linear classification and segmentation transfer tasks. Code and pretrained models are publicly available at: https://github.com/facebookresearch/VICRegL
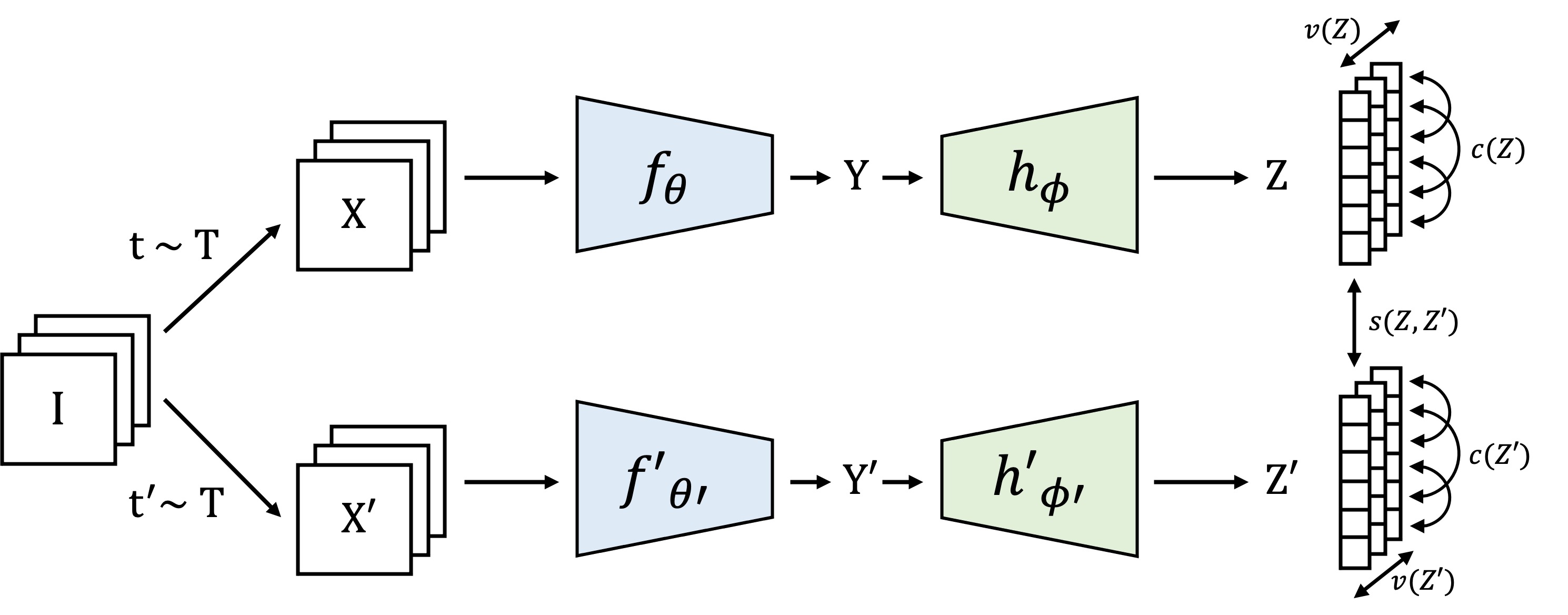
ICLR 2022
@inproceedings{bardes2022vicreg,
title = {VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning},
author = {Adrien Bardes and Jean Ponce and Yann Lecun},
booktitle = {ICLR}
year = {2022},
}
Recent self-supervised methods for image representation learning are based on maximizing the agreement between embedding vectors from different views of the same image. A trivial solution is obtained when the encoder outputs constant vectors. This collapse problem is often avoided through implicit biases in the learning architecture, that often lack a clear justification or interpretation. In this paper, we introduce VICReg (Variance-Invariance-Covariance Regularization), a method that explicitly avoids the collapse problem with a simple regularization term on the variance of the embeddings along each dimension individually. VICReg combines the variance term with a decorrelation mechanism based on redundancy reduction and covariance regularization, and achieves results on par with the state of the art on several downstream tasks. In addition, we show that incorporating our new variance term into other methods helps stabilize the training and leads to performance improvements.
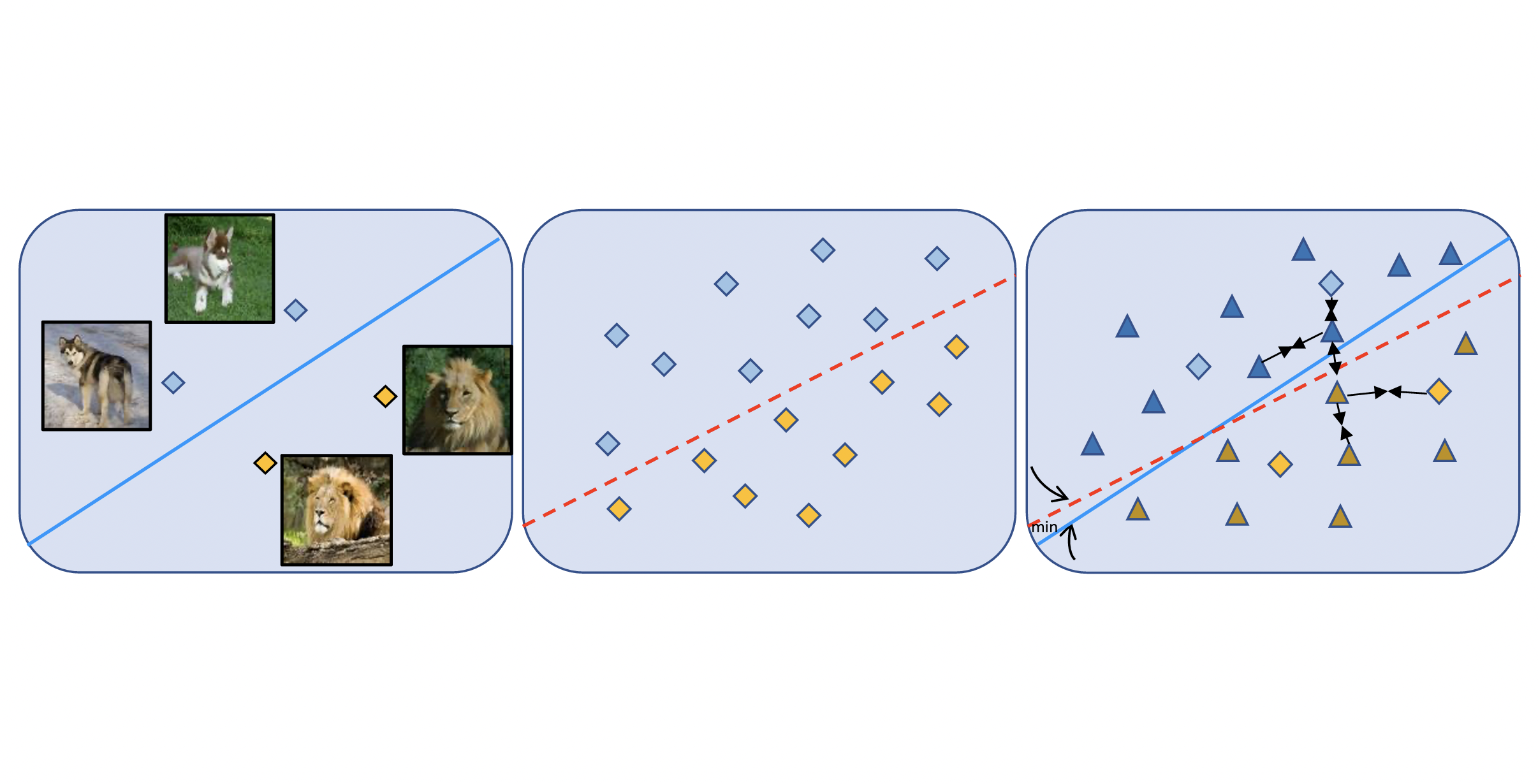
ICCV 2022
@inproceedings{gui2021dmas,
title = {Learning To Hallucinate Examples From Extrinsic and Intrinsic Supervision},
author = {Liangke Gui and Adrien Bardes and Ruslan Salakhutdinov and Alexander Hauptmann and Martial Hebert and Yu-Xiong},
booktitle = {ICCV 2021}
year = {2021},
}
Learning to hallucinate additional examples has recently been shown as a promising direction to address few-shot learning tasks. This work investigates two important yet overlooked natural supervision signals for guiding the hallucination process--(i) extrinsic: classifiers trained on hallucinated examples should be close to strong classifiers that would be learned from a large amount of real examples; and (ii) intrinsic: clusters of hallucinated and real examples belonging to the same class should be pulled together, while simultaneously pushing apart clusters of hallucinated and real examples from different classes. We achieve (i) by introducing an additional mentor model on data-abundant base classes for directing the hallucinator, and achieve (ii) by performing contrastive learning between hallucinated and real examples. As a general, model-agnostic framework, our dual mentor-and self-directed (DMAS) hallucinator significantly improves few-shot learning performance on widely used benchmarks in various scenarios.
Talks
- Self-supervised learning, theory and applications, Swood Partners, 2023
- Self-supervised learning of local visual features, Mila Computer Vision Meeting, 2022
- Self-supervised learning and thrust-worthy AI, Confiance.AI, 2022
- Self-supervised learning of local visual features, NeurIPS poster session, 2022
- Variance-Invariance-Covariance for Self-Supervised Learning, ICLR poster session, 2022
- Variance-Invariance-Covariance for Self-Supervised Learning, FAIR Workshop, 2021
Teaching
- Object Recognition and Computer Vision, Project Advisor, Master level (MVA), ENS Paris-Saclay, Fall 2021
- Object Recognition and Computer Vision, Project Advisor, Master level (MVA), ENS Paris-Saclay, Fall 2022
Academic Services
- Reviewer for IJVC, ML (Springer), ICLR 2022-2023, NeurIPS 2022-2023, CVPR 2023, ICCV 2023.